Information Leakage as a Concept
In this post I am considering the topic of information leakage from one thing, the target, to another thing, the attacker. This is generally the goal of sidechannel attacks: the attacker wants to learn some information the target wants to keep secret. However, in my experience, sidechannel attacks (and corresponding defenses) are very narrowly scoped. This narrow scoping makes sense because many sidechannel attacks rely on very specific aspects of the environment or target to work and much of the hard work - both thinking and engineering - have to be focused on these low-level details. However, this narrow scoping can make it difficult to interact with these sidechannel attacks: compare different attacks; assessing risk of an attack under different circumstances; or determing cost effectiveness of a defensive adjustment. In this post, I attempt to lay out a more general theoretical framework for what happens during a sidechannel attack to help with this challenge.
Example Cases
Throughout this post I will return to these two examples (among others) to illustrate concepts.
Website Fingerprinting
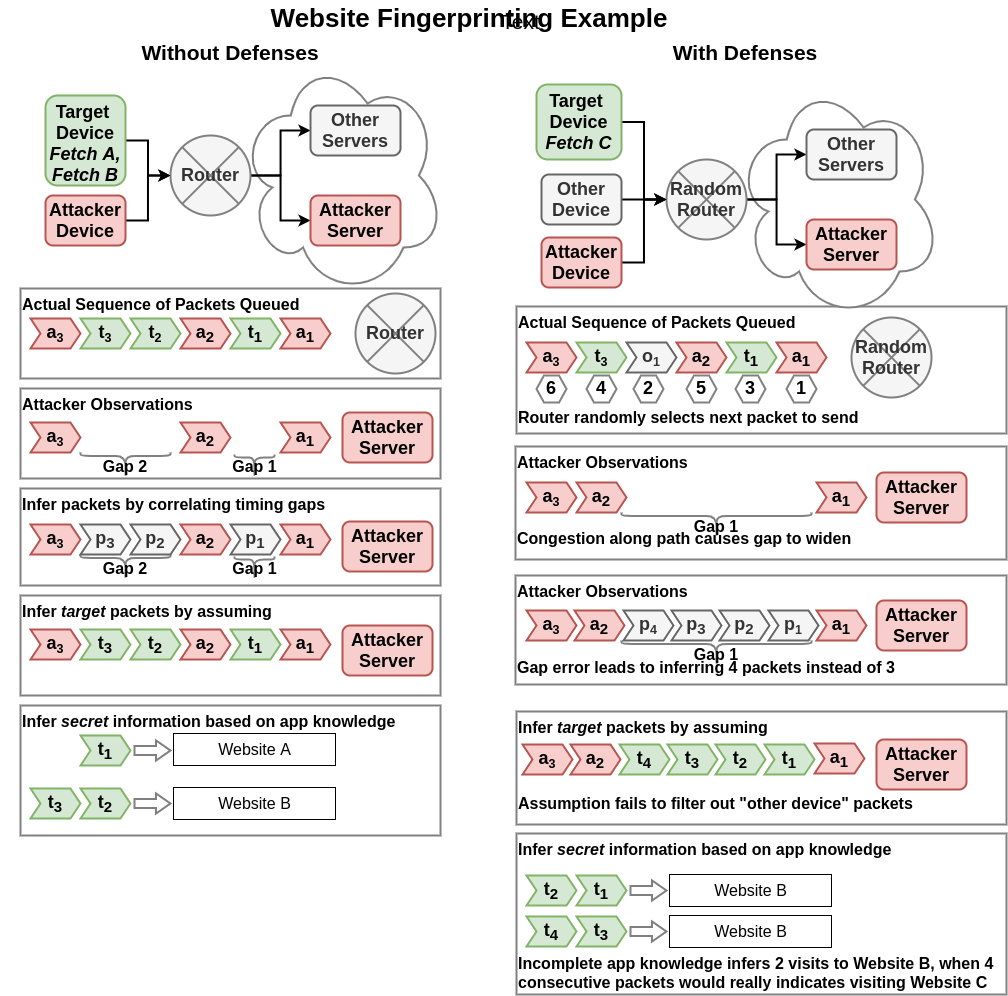
In this attack, the target is a web-browsing client and the information they want to keep secret is which webpage they are visiting. Initial assumptions are that the communication contents are successfully encrypted, so the attacker will attempt to infer which webpage is visited based on the pattern of packet timings and sizes.
To make this a better example for illustrating the theory, the attacker is not assumed to be “on-path” and able to directly observe packets destined for the target. Instead, the attacker is “off-path” and only able to observe those details by observing the delays of its own probe packets sent through a router shared with the target.
Cache Timing
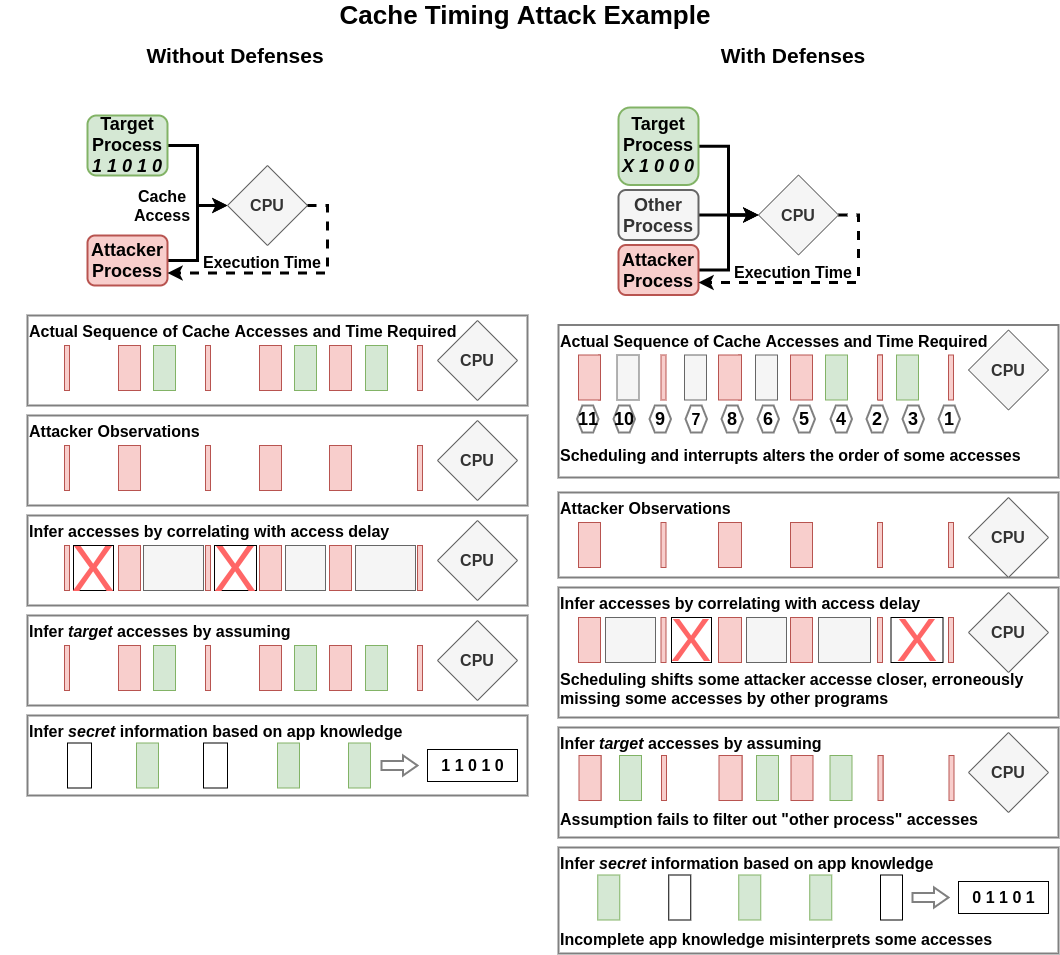
In this attack, the target is a process on shared hardware with an attacker process. The secret information is a cryptographic secret (like an RSA private key) that influences the branching of the target process: when a branch is taken, the target fetches that instruction and so fills the corresponding cache-line with that address. When the branch is not taken, the cache is unchanged.
The attacker attempts to infer this secret by conducting one or another cache timing attack[Kayaalp2016, Yarom2014] that allows them to observe whether a certain cache line has been accessed or not. This allows the attacker to then determine if the branch was taken or not, and thus infer a bit of the target secret.
A Theory in Three Pieces
Looking around at various sidechannel attacks, I am proposing a fairly simple but hopefully still useful 3-function / layer formalism:
- Signal Acquisition
- Signal Isolation
- Information Inference
I think every sidechannel attack implicitly includes all three layers, but often elide 1 or 2 of them for various reasons. This elision is usually specified in the threat model of the research work developing the attack, but the impact of changing that threat model is typically never explored (apologies to any that do, I don’t have an exhaustive knowledge of sidechannel attack research papers). The crux of this post is that understanding how a changing threat model affects these attacks is critical to understanding the risk and tradeoffs of defending these attacks in the real world.
1. Signal Acquisition
The first stage of the attacker process is acquiring a signal from the sidechannel that somehow correlates with the target information they want to extract. Essentially, the attacker hypothesizes that the target information is reflected as some correlated perturbation in the sidechannel, and so they need to be able to read that perturbation.
In the website fingerprinting example, this stage corresponds to the attacker converting its probe delays into an estimate of the traffic passing through the router (all traffic, not just the target traffic). In the cache timing example, this stage corresponds to the attacker converting the delay in reading the cached address into an estimate of whether some other process accessed memory corresponding to the same cache entries (any process, not just the target process).
I would claim this is the most-often studied part of the three, because it is the first thing that must be established to claim a sidechannel attack is plausible: if there is no way for the attacker to discern differences in signal based on the changes in the environment (like target actions, among other things), then there is no way to proceed.
Defenses in this area are aimed at breaking the correlation between environment conditions and attacker-observed signals. In the website fingerprinting example, there are various privacy-preserving scheduling routines that can do this. The signal to the attacker is essentially the correlation of attacker probe delays and target traffic; a scheduling algorithm that eliminates that correlation eliminates the sidechannel.
In the cache timing example, a similar defense could reschedule process threads to disrupt the ordering the attacker expects. However, a more practical (and proposed) defense is reducing the accuracy of timing information the attacker can obtain. This has lead to other, non-timing-based sources for cache sidechannel attacks.
2. Signal Isolation
The second stage of the attacker process is sorting out the target’s signal from signals causes by all the other processes operating on the same shared resource. Since the signal acquired in stage 1 is inferred from monitoring the aggregate behavior of a shared resource, that signal naturally combines the impacts of all uses of the resource.
In the website fingerprinting example, this stage corresponds to differentiating packet delays caused by the target’s packets being processed versus delays caused by any other network application sending traffic through the same router. This could potentially be done using models of network traffic - e.g. if a continous stream of real-time data was interfering it could potentially be characterized and filtered out. I am not sure if there are established techniques for doing this in a more general way; it seems like a very tricky problem likely to be very dependent on exactly what traffic is interfering. In the cache timing example, this stage corresponds to differentiating cache writes caused by an access by the target process versus another process. For cases where the target application is repeatedly accessing the same few pieces of memory, as most canonical cache timing attack targets are, then interference might typically be low. However, as with the website fingerprinting attack, I do not think this is a trivial process for more general scenarios.
This seems, to me, to be the most often elided stage of sidechannel attacks and results are usually gathered in an isolated environment with just the attacker and target. This is understandable for a few reasons: first, there is not usually an easy “realistic scenario” to use; second, additional processes are just adding a linear amount of noise to the signal - so if a sidechannel attack works in an isolated environment it is reasonable to assume that, after some improvements, it will work in a more realistic environment; third, isolated environments aren not necessarily unrealistic because the attacker may have the capability to force that isolation.
Defenses in this stage are about adding noise and confounding the ability for the attacker to filter out that noise. In the website fingerprinting example this could be done by adding more network traffic via some kind of generator or network change to pull in more legitimate network processes. In the cache timing example this could similarly be adding more processes that use the cache in unpredictable ways or adding random cache accessing processes just to introduce noise (as seen in ).
This is the simplest place to introduce a defense, but I think it is also probably the least-efficient: assuming resource usage is valuable, adding useless noise is a significant cost. Furthermore, the benefit is limited: adding a linear amount of noise is only reducing the information gained by the attacker by a logarithmic amount.
3. Information Inference
The third stage of the attacker process is taking the filtered signal of the target and using it to infer some type of information the attacker is actually after. This essentially involves having a model of the target process mapping sidechannel signal to the secret information.
In the website fingerprinting example this stage is the main challenge in most research: given a perfect signal of packet lengths and/or timings (eliding Stages 1 and 2), infer which website was being visited. In the cache timing example this stage corresponds to identifying what the target process did based on its cache accesses. Unlike website fingerprinting, most cache timing sidechannel attacks elide this stage by selecting a target application that maps very directly from signal to information: the canonical example seems to be RSA private key operations where a 1-bit in the key causes a cache access and 0-bit does not.
Defenses at this stage are about reducing differences in signal caused by important differences in the process. In formal methods terminology, the desire is to make two executions of the process using different secret information equivalent with respect to the observal signal. Existing website fingerprinting defenses do this by altering the packet timings and lengths, using a few different methods, to try to make visits to different websites appear equivalent. Since network proxies are relatively common and easily deployed, these defenses appear practical and easier than altering router firmware (which is often out-of-scope for private user targets). Conversely, these defenses are considered significantly more costly for cache timing attacks, because they involve modification to the application code. Since the chosen target applications are typically cryptographic code and act as bottlenecks to the application, altering them and potentially decreasing efficiency is usually not an attractive option.
Utility of the Theory
So, is this theory of sidechannel leakage in 3 stages a useful one? Well, I unfortunately do not have any immediate grand insights (otherwise this would probably be a paper instead of a blog post). However, I think there are a few highlights to pull out and think about:
First, realizing that most sidechannel attack papers focus on proving one of these three stages can be done is helpful to see which pieces they are eliding. After that, you can hopefully quickly find their rationale for why the other stages are being elided: does previous work already accomplish it, or do they restrict the scope to assume a simpler scenario where the other stages are trivial?
Second, understanding what has been elided can help to evaluate what kind of defense makes sense under realistic circumstances. Since the real world situation may be significantly different than whatever made the sidechannel attack easiest to proof-of-concept. The website fingerprinting example assumes preventing signal acquisition or adding noise is out of scope of the defender. However, if the real defender is an organization that could customize its routers or request its provider to do so, or that could affort to add some noise generation, then those defenses are in scope.